Replacing Planetscale

Now that Planetscale is ditching their free tier, I need a new database for the free GitHub app that I maintain. There were three reasons I picked Planetscale in the first place:
- Aaron Francis
- It was free
- The branching workflow for schema changes
If you want more Aaron, consider buying his course. To address the other two reasons, I’m splitting this blog post in two parts:
That way, if you only care about one or the other, you can read just that piece. Now, on with the show!
The database
First, let’s talk requirements. The database for this app needs to be:
- Cheap or free. I don’t want to spend more than the GitHub sponsors for Knope are bringing in.
- Vitess-compatible. Data migration should be easy, and I don’t want to rewrite all the queries.
- Durable enough. Some basic periodic backups should be fine. I don’t need high availability.
- Close to the app. Less latency means less app runtime, which means less cost.
Hosting providers
I can broadly categorize the places to host a database into three buckets:
- Database as a service (DBaaS)
- Hyperscaler managed databases
- DIY databases on smaller clouds
Databases as a service were eliminated pretty much immediately. The cheapest one I could find was $15/month. I guess Planetscale was the only one offering a real free tier (their cheapest is now $39/month, by the way).
If I were to pick a hyperscaler, it’d be AWS since this app was running on AWS Lambda within its free tier (I’ve since moved it to the same provider as the database). I also have managed RDS in production before, so the learning curve wouldn’t be too steep. However, the free tier for RDS is time-limited, and the cheapest possible price I could find is twice as expensive as the cheapest DBaaS. So that leaves the third option.
When it comes to the smaller clouds, there’s only one choice. My Railway account is old enough to still get $5/month for free, and I’ve accumulated some credits through referrals (with templates and links like the ones in this post). That means, as long as I keep it below $5/month, I can host the databases and the app for free. If I go over, I have some credits to sustain the app for a while until it gets sponsors 🤞.
Database technology
Deploying my own database on Railway means I can pick whatever database technology I want. The two main options that are compatible with Vitess are MySQL and MariaDB. MySQL has an official template which can be deployed with a couple clicks, so that’s what I chose. Yes, that really is why. Developer experience matters.
Setting up MySQL
After deploying the template, I enabled app sleeping to save on credits (and energy usage) when the app
is not in use.
Next, I copied over the schema from Planetscale to Railway.
I used Atlas, but mysqldump would work just as well for this part.
Juggling databases
There are a bunch of well-documented strategies for cutting over databases, so I recommend you look for one that best suits your needs if you’re doing something similar. For me, most of the data is a cache of GitHub data, so I didn’t need everything, just the frequently accessed things (to avoid flooding GitHub’s API with requests). To achieve this, I:
- Added a connection to the new database
- Changed all queries to read from the new database first. If data was missing, it read from the old database and wrote the missing data back to the new one
- Let it run for a few days to capture the majority of the data
Once I was satisfied that the remaining gaps were small enough, I removed the connection to the old database, and I was done! Well… almost.
Backups
The official template doesn’t have automatic backups. I don’t need anything too fancy, just a recent snapshot so I can restore the necessary bits if something catastrophic happens at a datacenter. I checked out the existing templates on Railway, and none of them quite did what I wanted, so I made my own (as well as a template which bundles MySQL and the backup job for even fewer clicks!).
This leverages Railway’s built-in cron feature to take a snapshot periodically—so the backup process itself is only running (and costing me credits) when necessary. This also gives me a handy “Run now” button to make one-off backups for testing.
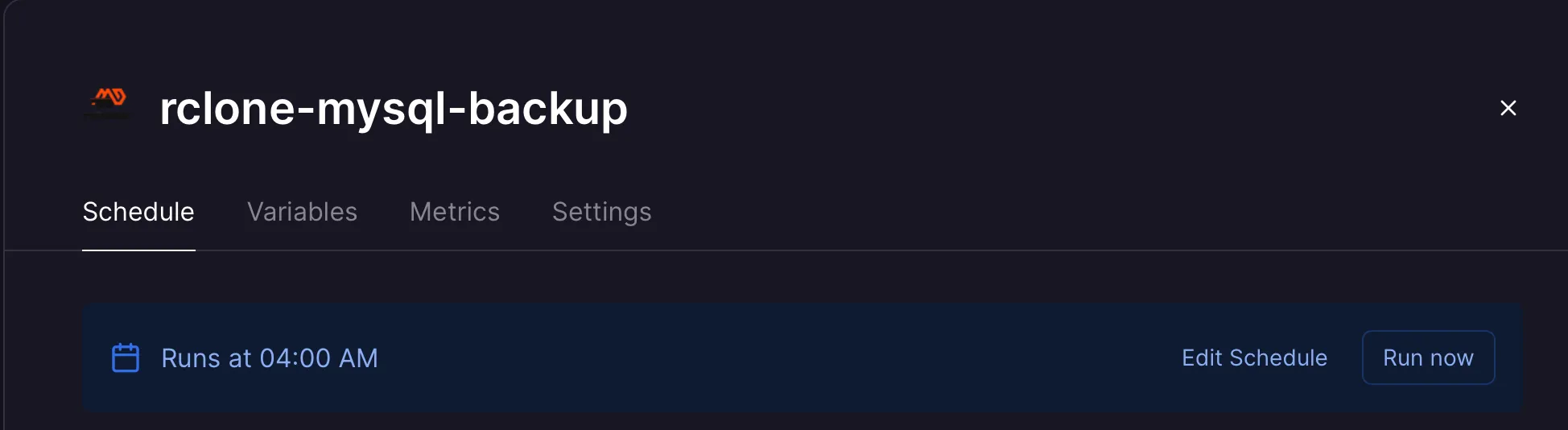
Internally, it uses mydumper, a faster alternative to mysqldump, to take the snapshot.
Then, it uses rclone to push that snapshot to a Cloudflare R2 bucket.
My usage will stay well within the free tier of R2, so this is effectively a free backup for me.
Remember, no backup is complete until you’ve tested restoring from it! I did that on a local MySQL instance and it worked great.
How much does it cost?
This is not going to be indicative of your costs—my app is very bursty, so the database can spend a lot of time sleeping. Railway is also very bad at estimating costs for apps that sleep. Plus, there’s some sort of bug in the per-service breakdown where disk usage isn’t covered. But, after running for about 2 weeks, my two sleepy MySQL instances have cost around $0.61. So for a month of usage at the current rate, I’d expect the total cost to be around $1.50. That’s plenty of headroom before I hit my $5/month free limit and need to start using credits (though, this isn’t the only project I’m running on Railway).
In case you’re curious, the app itself is set to cost around $0.04/month while sleeping at about the same rate as the databases. Rust on the backend can make for some very economical apps!
The backup job says it’s costing $0.00, so I guess it’s quick and infrequent enough to be a rounding error!
The workflow
One of the main reasons I picked Planetscale in the first place was the ability to propose changes from one database schema to another. Iterating directly on the test database while developing, then applying those changes to production is much nicer than the typical migration script approach.
I chose Atlas to replicate this. It has a lot of features, but the important parts for me are inspecting a database, storing the schema as HCL (HashiCorp Configuration Language), and applying that schema to another database. Using this tool, my workflow looks like this:
- Make changes directly to a test database while iterating on a new feature.
- In GitHub Actions, automatically inspect the database and keep the HCL up to date.
- When the feature is done, review the HCL schema changes in the pull request in GitHub.
- Once the PR is merged, apply the changes to the production database in CI before the service is updated.
As an extra layer of validation, the app connects to the database while building to ensure that the schema is up-to-date. If something goes wrong with this process, the build will fail (rather than queries failing at runtime). If your database library offers this feature (like sqlx does), I strongly recommend it.
Here’s what the actions look like:
on:
pull_request:
paths:
- ".sqlx/*"
jobs:
update-schema-file:
runs-on: ubuntu-latest
permissions:
contents: write
steps:
- uses: actions/[email protected]
with:
repository: ${{ github.event.pull_request.head.repo.full_name }}
ref: ${{ github.event.pull_request.head.ref }}
- uses: ariga/setup-atlas@master
- name: Update schema file
run: atlas schema inspect -u ${{ secrets.TEST_DATABASE_URL }} > .sqlx/schema.hcl
- uses: stefanzweifel/git-auto-commit-[email protected]
When there’s a pull request that affects a file in the .sqlx directory, Atlas inspects the test database and saves its
schema to a file.
The format is HCL, though that doesn’t really matter to me, as long as it’s readable.
This file is then committed back to the repository.
This prevents the HCL file from being updated for unassociated pull requests, like automatic dependency updates. That
.sqlx folder gets updated whenever I change queries in the app, so it’s a good signal that the schema might need updating.
If I need to manually update the schema, say for an index-only change, I can do that by running the same command locally.
For extra credit, you can also set up a periodic job to check the schema and, if it’s changed, open a pull request with the updated HCL. This would work as drift detection.
When the HCL file changes on the main branch, this next workflow updates the production schema automatically:
on:
push:
branches:
- main
paths:
- ".sqlx/schema.hcl"
workflow_dispatch:
jobs:
update-prod-database-schema:
runs-on: ubuntu-latest
steps:
- uses: actions/[email protected]
- uses: ariga/setup-atlas@master
- name: Update schema
run: atlas schema apply -u ${{ secrets.DATABASE_URL }} -f .sqlx/schema.hcl --auto-approve
So my schema changes are tied to my pull requests, I can review the changes as part of the PR, and when I merge to main to deploy to production, the database gets updated too!
This workflow relies on having one test database per PR, which works for me because I’m only working on one major feature at a time. If you’re working on a team, you’ll want to check out Railway’s PR environments or use a local workflow for updating the schema.
Wrap-up
That’s it! I’ve replaced Planetscale by running MySQL on Railway, sending backups to Cloudflare R2, and managing my schema with Atlas in GitHub Actions. I’m actually happier with this setup than I was with Planetscale. My metrics are showing the slowest queries as 10x faster, even when the database was sleeping! Atlas is also a nicer solution for schema management; auto-deploys were much easier to set up, and I can see the schema diff right next to my code diff.
If there’s any part of this solution you’d like me to dive deeper into, let me know! I’d also love to hear about your database setup and how it’s working for you (particularly migrations).
Was this post super helpful to you? Tip me on GitHub, Patreon, or Ko-Fi.
Have a question or comment about this post? Leave it in the discussion thread on GitHub!
Want to be notified of future posts? Watch releases in the GitHub repo or follow me on Mastodon
Have an idea or request for a future blog topic? Drop it in the GitHub discussions under ideas.